

テーマ:やってみた


業務中の集中度を機械学習で推定してみました!
2021年4月19日
ユーザビリティの若手メンバーが、プログラミングやデータ分析スキル磨きつつ、日々の業務の生産性や効率を上げようという取り組み「やってみたシリーズ」。第2回は、第1回の続きとして、「業務時の集中度」を「様々な日常の行動」から推定することができるか、機械学習を用いて分析してみました!
○第1回の簡単な振り返り
【自分たちの最大限の力を発揮するためには、どんな生活スタイルを送るのが良いのか?】を実際に調べてみよう、ということで、若手5人で2~3か月間、「様々な日常の行動」と「業務時の集中度」を記録していきました。
○データの分析方針
今回は、「業務時の集中度」を「様々な日常の行動」から推定できるかどうかを分析してみました。
もし日々の行動と集中度に関係があれば、その人が仕事に集中できるような行動を提案してあげたり、良くない行動をしているときに注意してあげることができそうですね。
また、今回取得した「日常の行動」は、睡眠時間・食事の有無・在宅か出社か…等、多種多様な項目があるため、分析手法には機械学習を用いました!(具体的な手法については長くなるので今回は省きます)

○分析結果
5人分のデータを集めて、欠損や記録ミスなど、分析のノイズとなるデータを除くと、延べ61日分のデータが残りました。(最大で約300日分集まるはずだったので、比較するとかなり少ないですが、今回はこのまま分析を進めます!)
このうち、8割(48日)の学習データで機械学習モデルを作成し、残り2割(13日)のテストデータを推定してみました。
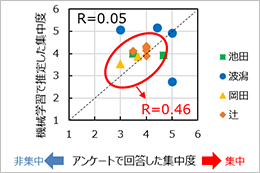
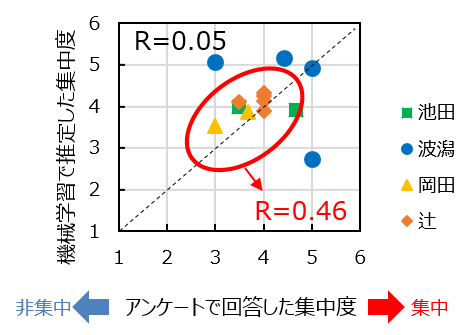
下の図2は、アンケートで実際に回答した集中度と、機械学習モデルから推定した集中度の比較です。
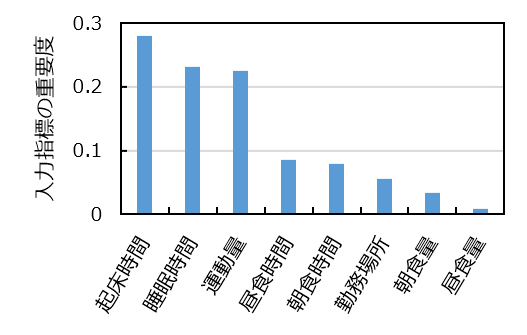
テストデータには4人のデータが混ざっているので、回答した人ごとにプロットを色分けしています。また図3は、モデルの学習時に、各入力指標がデータの分類にどれだけ寄与したかを示した重要度のグラフです。特に「起床時間」「睡眠時間」「運動量」の重要度が高くなっています。
図2では、モデルがうまく学習できていれば、データは点線に沿ってプロットされるはずですが、全体で見ると相関係数が0.05と、あまり良い数値ではありません、、
一方で、人ごとに見ると、辻君(オレンジ)のデータは比較的点線近くにプロットされたり、岡田(黄色)のデータはアンケート得点が低いものは推定値も低くなっていたりと、傾向が追えそうな人もいます。逆に、波潟さん(青)のデータは点線からかなり外れているように見えます。そこで、図3で一番重要度の高かった「起床時間」について元のデータを見てみると、なんと、他の人は大体6時~7時半には起床しているのに対して、波潟さんは8時~11時に起床していたようです。(他の人より夜型ですね!)これを踏まえると、モデルが「波潟さんと他の人」を分類してしまい、その結果波潟さんだけ推定値の傾向が変わってしまった可能性があります。試しに波潟さんのデータを外してみると、相関係数は0.46まで上がりました!人によっては、推定モデルを変える(その人にパーソナルフィットさせる)必要があることが示唆されました。
○課題と得られた知見
- データ収集の負荷が想定以上に重く、データ数が減少
第1回の記事で福田君も書いてますが、今回のデータ収集は、実はかなり大変でした!打合せや実験が立て込んでいて業務中の集中度が回答できなかったり、日常の行動データの記録を忘れてしまったりすることもありました。回答者に負担にならないような評価設計が大切だと実感しました。(プロダクト解析センターでは、表情からスポーツの観戦満足度を分析するサービスや、心拍・表情からリラックスを分析するサービスなど、客観的な指標を用いた人の分析サービスも実施していますが、そういった自動的に収集できる指標を使うことも有効だと思いました。)
- 「業務中の集中度」の推定モデルが人ごとに違う可能性
今回は、データ数の観点から5人のデータをまとめて分析しましたが、得られた結果から示唆されるように、集中度を推定するモデルは人によって違うかもしれません。①の課題が解決して、1人1人のデータがたくさん取れるようになれば、個人差を考慮した分析や、今回記録しなかった「日常行動」の影響についても検討できると思います。


